März 2025
Die xSuite Helix Release Notes beschreiben kundenrelevante Produkteigenschaften, die neu hinzugekommen sind oder sich geändert haben.
Das Release „Astute Alpaca“ von xSuite Helix zeichnet sich besonders durch die Möglichkeit aus, eine textbasierte KI zur Extraktion von Dokumenteninhalten einzusetzen.
Ende vergangenen Jahres wurde mit der Belegsegmentierung bereits eine KI-Technologie eingeführt. Diese Technologie hat mittlerweile schon mehrfach ihre Leistungsfähigkeit in produktiven Umgebungen unter Beweis gestellt. Die Belegsegmentierung unterstützt die Beleglesung durch eine grafische KI zur Bestimmung der Position von relevanten Beleginhalten.
In diesem Release wird nun erstmals die optionale Nutzung einer textbasierten KI, einem Large Language Model, zur Extraktion von Dokumenteninhalten angeboten.
Der Einsatz eines Large Language Models für das Auslesen von Kopf- und Positionsdaten für Eingangsrechnungen ist nun möglich.
Die Beleglesung wurde auf der Ebene des impliziten Trainings deutlich verbessert.
Neue Funktionen
Auswahlmöglichkeit zum KI-basierten Auslesen von Beleginhalten der Kopf- Positionsdaten anhand eines Large Language Models
Möglichkeit zur direkten Ablage von Workflowvorgängen in ein Archiv der Version Archiv V2
KI-basiertes Auslesen von Eingangsrechnungen
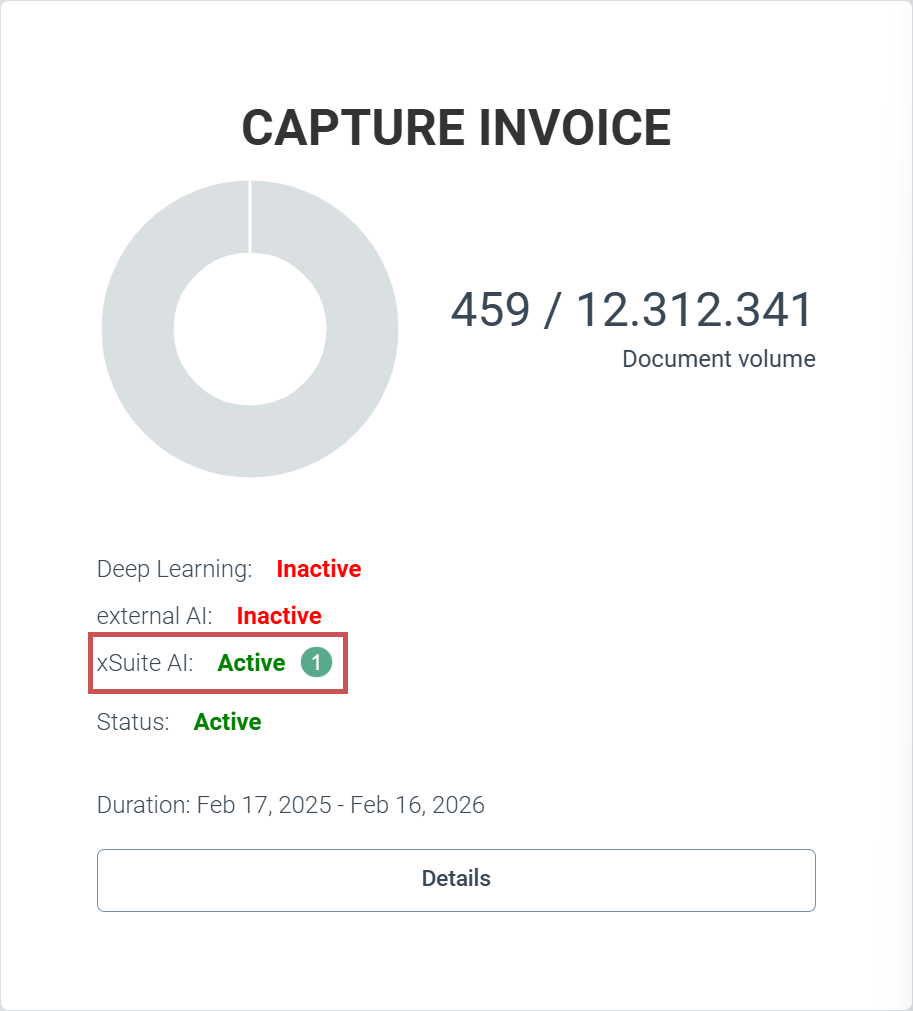
Die Beleglesung von xSuite Helix kann für Kunden mit Invoice-Premium-Paket optional auf die Nutzung einer textbasierten KI, einem Large Language Model, umgestellt werden. Die xSuite Group GmbH kann xSuite-Helix-Mandanten zentral für die Nutzung der textbasierten KI freischalten (1).
 |
Für jeden Workflow kann der Benutzer nun individuell zwischen der gewohnten Beleglesung und der KI-unterstützten Beleglesung umschalten. Dazu ruft der Benutzer die Konfiguration des jeweiligen Workflows auf (Kachel Konfiguration → Knoten Workflow (V2) → Workflows). Anschließend kann der Benutzer im Workflow den Knoten Extraktion auswählen (1).
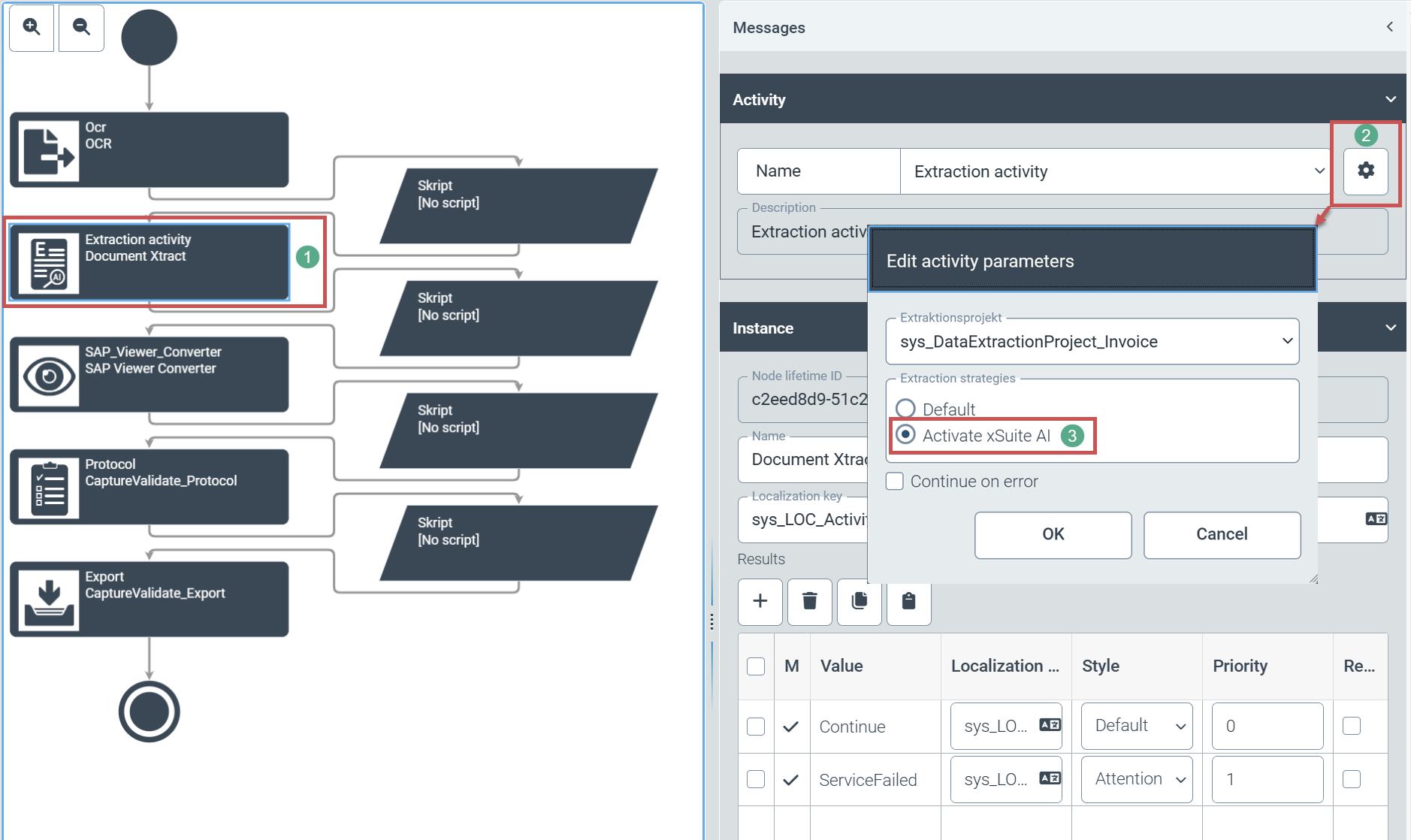 |
Über das Zahnradsymbol (2) öffnet der Benutzer die Parametereinstellungen des Extraktionsknotens. Der Benutzer kann in den Parametereinstellungen die KI-gestützte Segmentierung mit einem Klick auf die Option Aktivieren der xSuite KI Engine (3) auswählen.
Hinweis
Die textbasierte KI, xSuite AI, liefert immer Kopf- und Positionsdaten eines Belegs. Unabhängig von der gewählten Option zur Beleglesung kann der Benutzer das Auslesen der Positionsdaten in xSuite Helix nicht deaktivieren.
Direkte Archivablage von Workflowvorgängen
Feldinhalte von Workitems (Schemas), sowie Dateianhänge kann der Benutzer direkt aus einem xSuite Helix Workflow in das neue Archiv (Archiv V2) ablegen. Hierzu steht die neue Workflowaktivität Archive zur Verfügung.
Nur aus einem Workflowmandanten heraus kann der Benutzer Workitems inklusive der dazugehörigen Schemas sowie unterschiedliche Dateianhänge und Kommentare archivieren. Workflowvorgänge eines anderen Workflowmandanten kann der Benutzer aus seinem Workflowmandanten heraus nicht archivieren.
Voraussetzungen:
Im jeweiligen xSuite-Helix-Mandanten muss eine gültige xSuite-Archive-Lizenz für die Archivierung vorhanden sein.
Der xSuite-Helix-Mandant muss auf Archive V2 umgeschaltet sein.
Ein Archiv muss vorab vollständig angelegt sein.
Ablegen von Workflowvorgängen:
Der Benutzer legt einen Workflow im Kundennamensraum an. An der gewünschten Stelle des Workflows legt der Benutzer eine neue Aufgabe an. Die neu angelegte Aufgabe kann der Benutzer zur Archivierung auswählen (1).
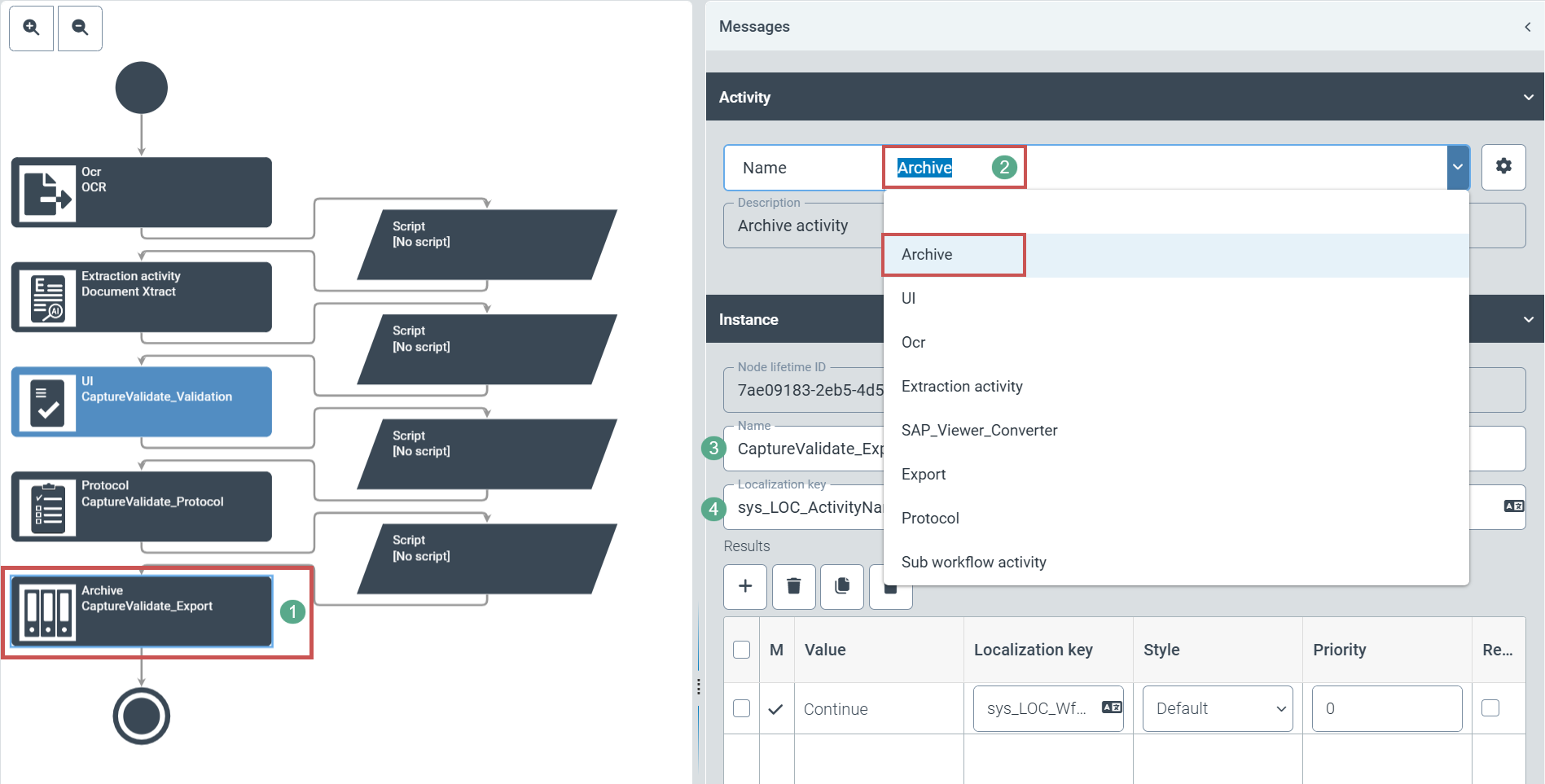 |
Als Aktivität wählt der Benutzer Archive (2).
Zusätzlich empfiehlt die xSuite Group GmbH einen geeigneten Namen (3) und eine Lokalisierung (4) zu wählen. Ansonsten sind später nur technische Namen an den betreffenden Stellen zu sehen.
Über das Zahnradsymbol (1) legt der Benutzer folgende Einstellungen für die Archivierung fest:
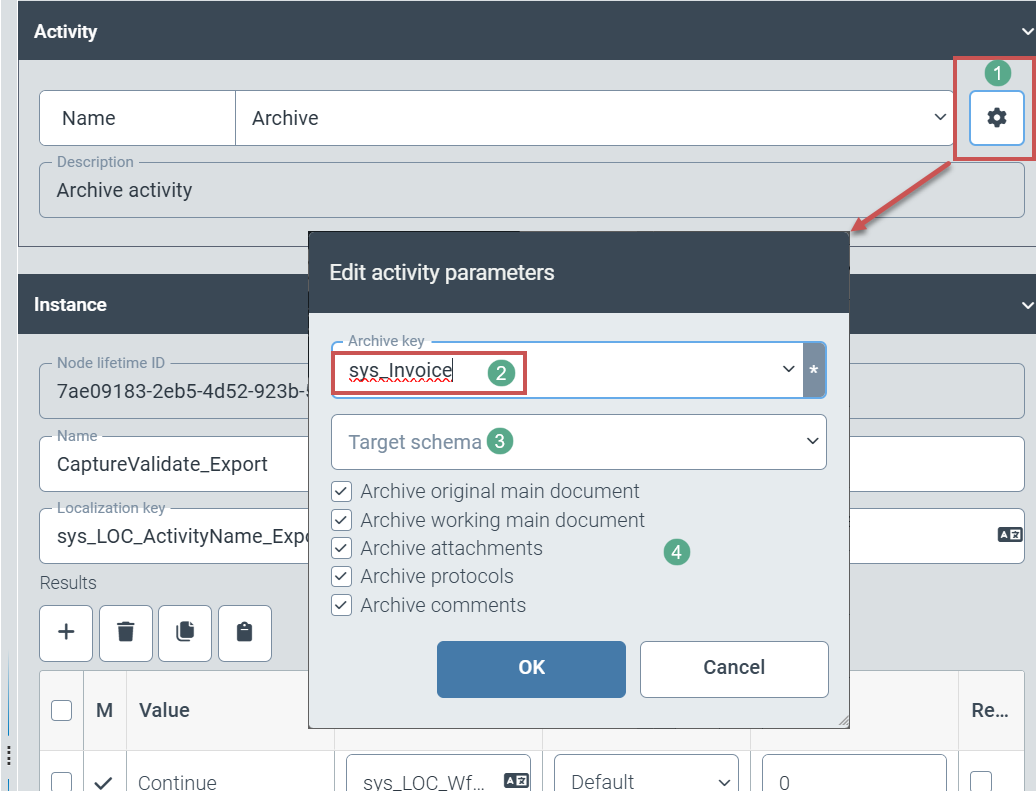 |
(technischer) Name des Archivs, in das Workflowvorgänge abgelegt werden (2)
Optional: Auswahl eines abweichenden Archivschemas (3).
Falls der Benutzer ein abweichendes Archivschema wählt, muss eine Datentransformation zwischen diesen Schemas über Allgemein/Core-Customizing in der Navigationsstruktur angelegt werden.
Auswahl der Workflowdokumente (Hauptdokument, Arbeitskopie des Hauptdokuments, Anhänge, Workflowprotokoll) und Informationen (z. B. Kommentare) für die Archivierung (4)
Änderungen
Verbessertes KI-Modell für die Belegsegmentierung
Erweiterte Rollenfindungstabelle mit einem dritten, frei definierbaren Kriterium für jede Regel
Erweiterte Sortier- und Filtermöglichkeit in der Rollenfindungstabelle für einzelne Regelspalten
Genauere Erkennung von Belegen gleicher Herkunft und verbesserte Unterscheidung von ähnlichen Belegen unterschiedlicher Herkunft beim Abrufen der Trainingsergebnisse
Beschleunigte Annahme und Verarbeitung von Stammdaten
Update der Belegsegmentierung
Die grafische KI zur Unterstützung der Beleglesung erhält ein Update des KI-Modells. Dieses Modell-Update verbessert die Geschwindigkeit. Zusätzlich wurden die Kriterien für das Erkennen der Felder während des impliziten Trainings stärker eingegrenzt. Dadurch ist die Erkennung präziser.
Zusätzliches Kriterium für Regeln der Rollenfindung
Die Rollenfindungstabelle wurde um ein drittes, frei definierbares Kriterium erweitert. Somit können Regeln zur Ermittlung von Bearbeiterrollen noch projektspezifischer festlegt werden.
Zusätzliche Sortier- und Filterfunktionen in der Rollenfindung
Für alle 3 frei definierbaren Kriterien zur Rollenfindung kann der Benutzer nun Sortier- und Filterdefinitionen festlegen. Die Kriterien zur Rollenfindung sind als Spaltenpaare in der Benutzeroberfläche sichtbar. Der Benutzer kann die Einträge dieser Spalten nun sortieren und filtern.
Verbesserte Identifikation von Belegen gleicher Herkunft
Belege gleicher Herkunft werden beim Abrufen der Trainingsergebnisse mit größerer Genauigkeit erkannt. Der Grund dafür ist die Anpassung mathematischer Regeln für den Erkennungsprozess.
Beschleunigung der Stammdatenannahme
Ein überarbeiteter Annahme- und Verarbeitungsprozess hat die Verarbeitung von übertragenen Stammdaten beschleunigt. Darüber hinaus werden Stammdaten nun in einer separaten Verarbeitungslinie verarbeitet. Die entkoppelte Verarbeitung der Stammdaten beschleunigt die Stammdatenannahme ebenfalls.